
안녕하세요, 이번 시간에는 우선순위 큐를 배워보려고 합니다. 뭔가 시작전에 어떤 말을 해야 할지 깊게 고민을 했는데 딱히 할 말이 생각나는게 없습니다. 그냥 바로 본론으로 들어가겠습니다.

우선순위 큐는 구현이 그렇게 막 어렵지는 않아서 원래 하던 대로 구현을 같이 해볼 예정입니다.

먼저 우선순위 큐가 뭔지를 알아보면 저희가 큐는 앞에서 배웠기 때문에 알고 있습니다. 큐는 마치 공항에서 입국수속을 하는 줄과 같이 원소가 추가되는 곳과 원소가 제거되는 곳의 위치가 반대여서 먼저 추가된 원소가 먼저 나오는 자료구조입니다. 반면 우선순위 큐는 pop을 할 때 가장 우선순위가 높은 원소가 나오는 큐입니다. 예를 들어서 우리가 주말에 펑펑 놀다가 일요일 밤부터 급하게 숙제를 하는 상황을 생각해봅시다. 그러면 숙제를 큐에 쌓아뒀다가 마감 시간이 가장 임박한 것 부터 하나씩 쳐내야 합니다. 이럴 때 우선순위 큐를 사용할 수 있습니다.
우선순위 큐는 원소의 추가, 우선순위가 가장 높은 원소의 확인, 우선순위가 가장 높은 원소의 제거 이 3개의 기능을 제공합니다. 그리고 그냥 배열로 쉽게 구현하면 세 연산의 시간복잡도가 각각 O(1), O(N), O(N)이 되겠지만 힙이라는 이름의 구조를 이용하면 세 연산을 O(lg N), O(1), O(lg N)에 처리할 수 있습니다.

과연 힙이 무엇이길래 저 연산들을 꽤 빠르게 처리해줄 수 있는건지 같이 살펴보겠습니다. 힙은 이진 트리 모양을 가지고 있습니다. 이진 트리는 앞 단원에서 언급했듯 각 정점의 자식이 최대 2개인 트리를 의미하고 힙은 이진 검색 트리와는 다릅니다. 은근히 이진 검색 트리와 힙을 헷갈려하시는 분들을 많이 봤는데 둘은 이진 트리라는 공통점만 있을 뿐이고 다른 자료구조란걸 기억하셔야 합니다. 우리는 힙을 최댓값 혹은 최솟값을 찾는 목적으로 쓸 수 있고 최댓값을 찾기 위해 사용하는 힙을 최대 힙, 최솟값을 찾기 위해 사용하는 힙을 최소 힙이라고 합니다.
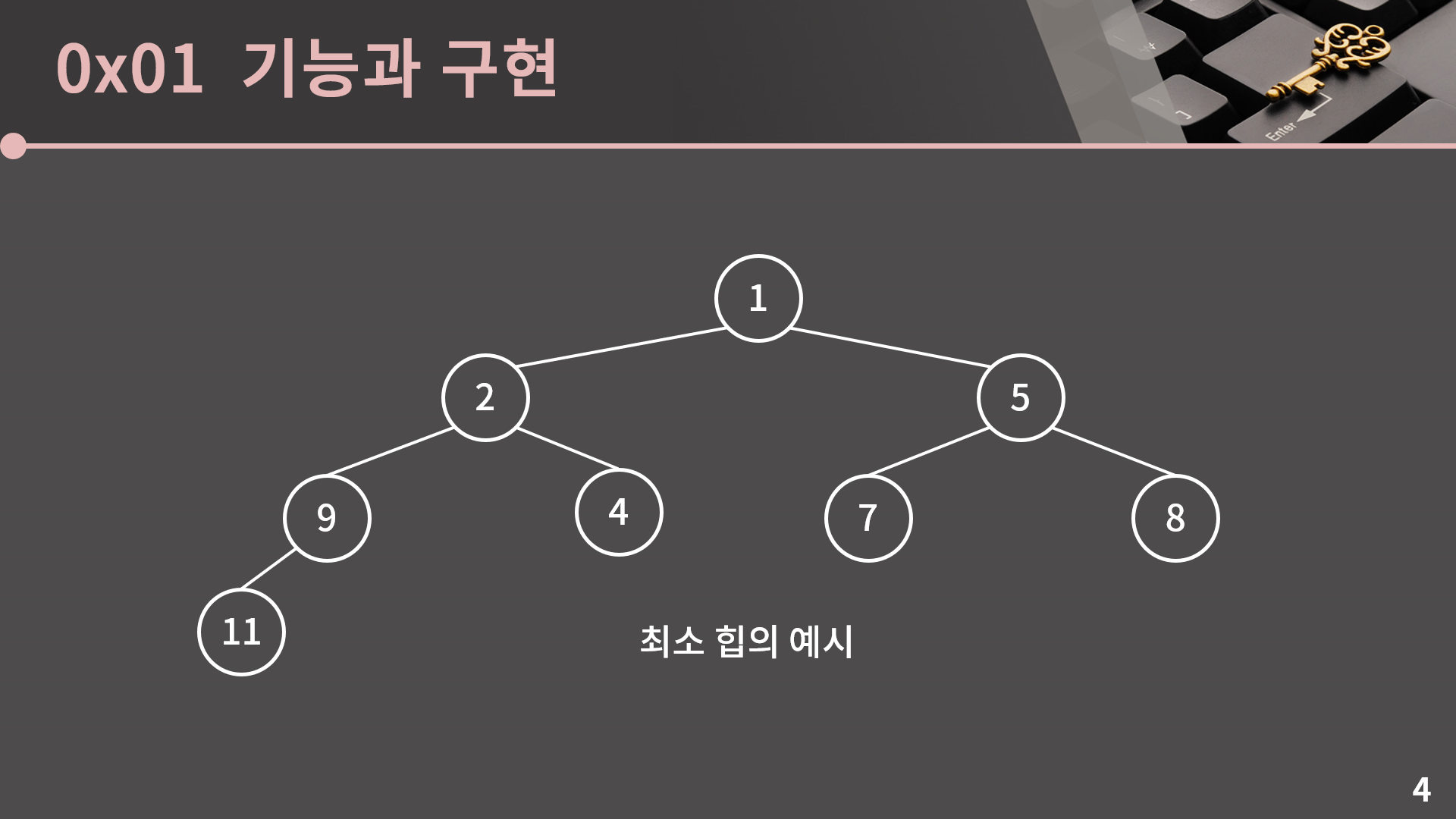
지금 이 그림이 최소 힙의 예시인데 최소 힙에서는 부모가 자식보다 작아야 하고, 최대 힙에서는 부모가 자식보다 커야 합니다. 예를 들어 2의 자식은 4와 9인데 둘 다 2보다 큰걸 확인할 수 있습니다. 이렇게 배치를 하면 자연스럽게 루트에 있는 값이 가장 작은 값이 됩니다. 만약 최대 힙이었다면 루트가 가장 큰 값입니다.

그리고 힙에서는 삽입하는 순서가 이 그림과 같습니다. 높이가 낮은 곳 부터, 높이가 같은 정점의 경우에는 왼쪽부터 채워나갑니다. 이런 방식으로 채우니 이진 검색 트리와는 다르게 힙은 불균형이 발생하지 않고 늘 균형이 잘 맞는 이진 트리가 됩니다.

힙이 뭔지는 알았으니 이제 각 연산들을 어떻게 수행할 수 있는지 바로 알아보겠습니다. 먼저 원소의 삽입부터 해보겠습니다. 일단 처음에 35를 삽입하면 35는 바로 루트입니다.

다음으로 55를 삽입하면 일단 앞에서 본 것 처럼 삽입하는 순서 상 원래 와야 하는 위치에 두겠습니다. 그리고 35는 55보다 작기 때문에 부모가 자식보다 작아야 한다는 성질을 잘 만족합니다.
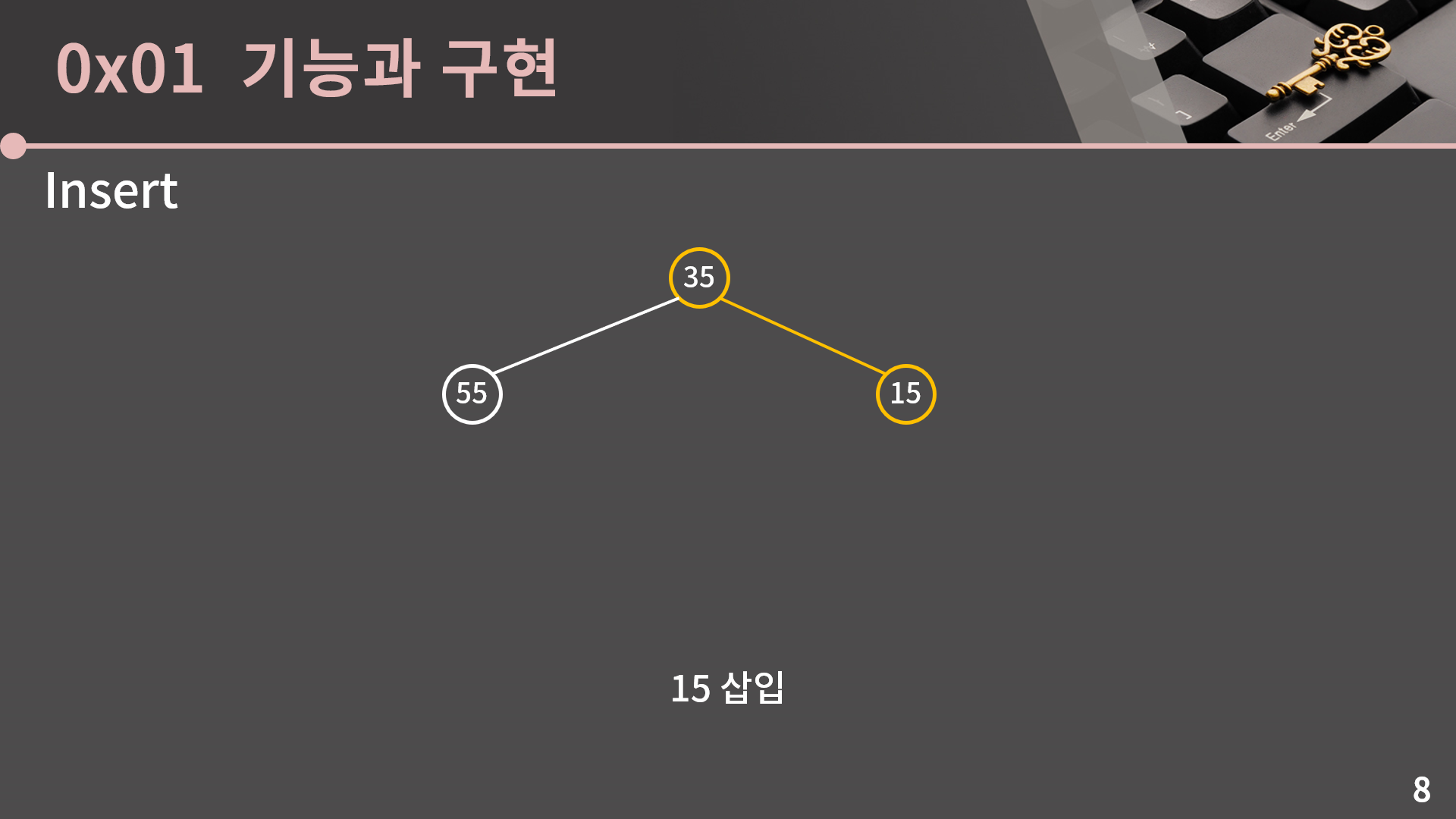
다음으로 15를 삽입하면 좀 재밌어집니다. 일단 15를 다음 위치에 넣긴 했는데 35와 15에서 최소 힙의 조건이 위배됩니다. 이걸 어떻게 해결할 수 있을까요?

해결은 아주 간단한데 그냥 둘의 자리를 바꾸면 끝입니다. 이렇게 15의 삽입을 잘 처리했습니다.

다음으로 8을 삽입해보겠습니다. 이번에도 마찬가지로 최소 힙의 조건이 위배되어서 뭔가 조치가 필요합니다.

당황할 것 없이 먼저 8과 55의 자리를 변경합니다. 이렇게 하면 8과 55 사이의 문제는 해결됐는데 이제는 8과 15가 말썽입니다.
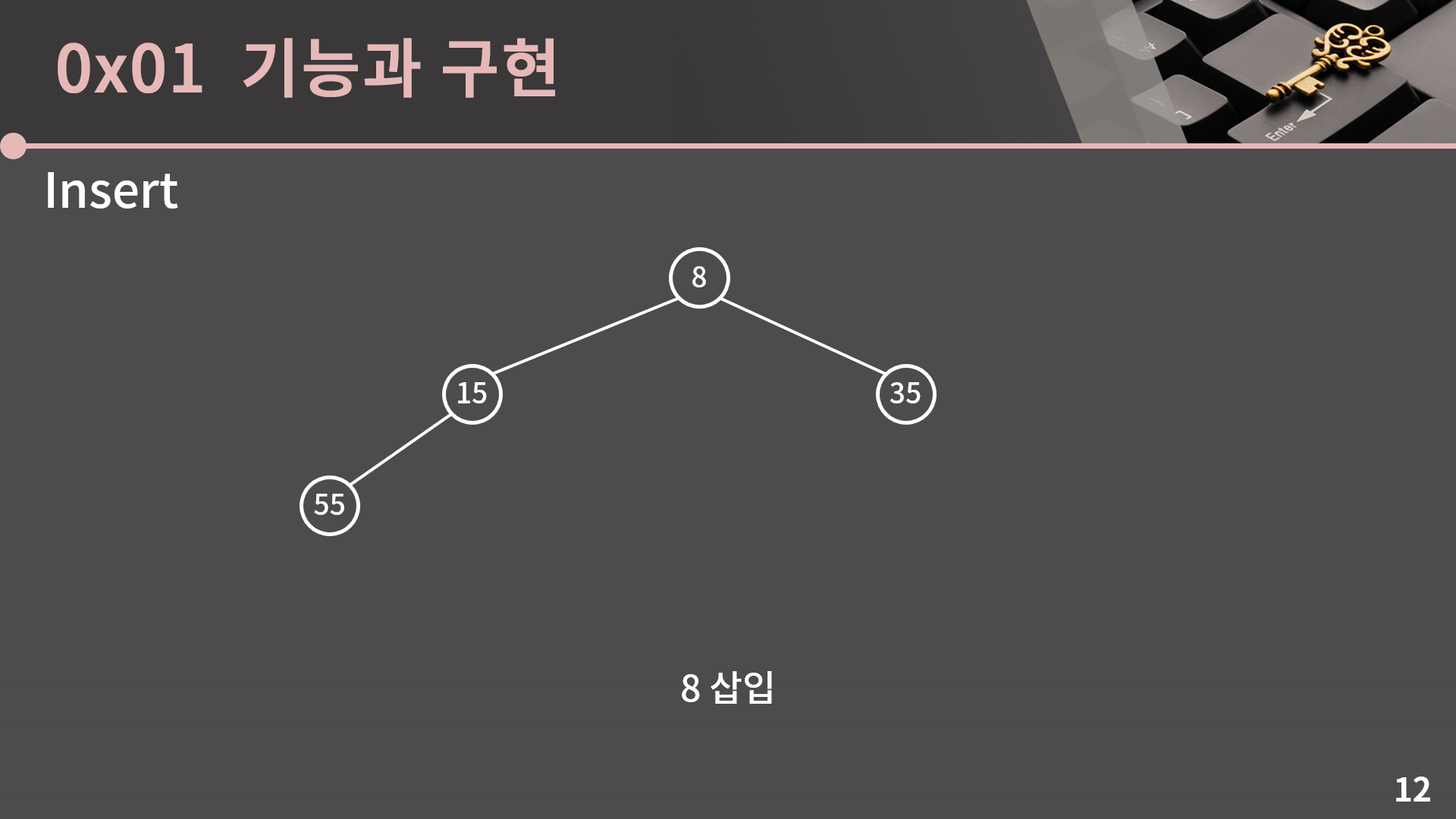
자연스럽게 이 둘의 자리도 바꾸면 삽입이 잘 끝납니다.
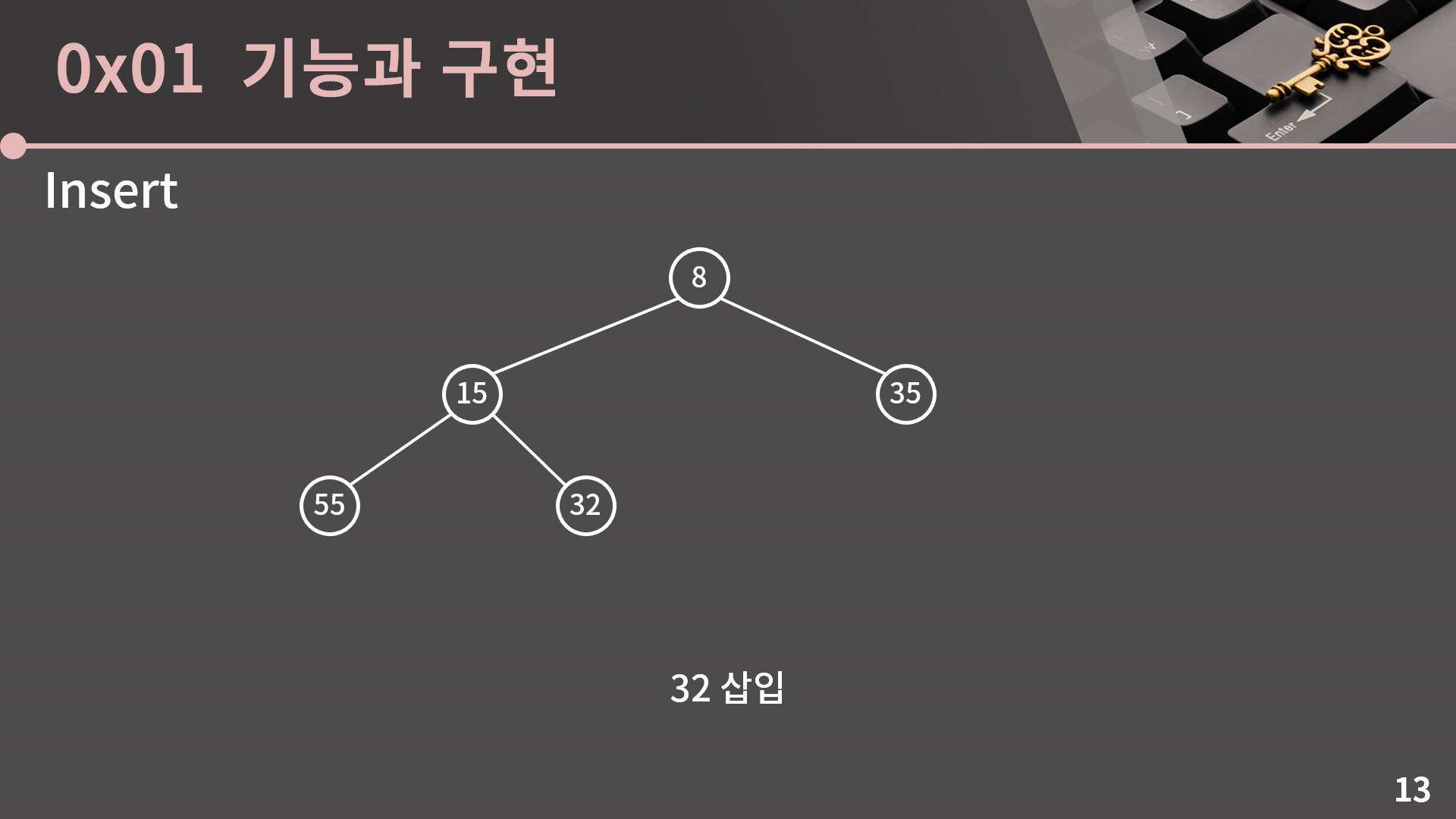
마지막으로 32를 삽입해보면 이번에는 문제가 안생겨서 그대로 끝납니다. 과정을 보면 알겠지만 매번 삽입을 할 때 마다 아무리 비교를 많이 해도 최대 높이 만큼만 올라가면서 자리를 바꿔주면 끝나고, 힙의 구조상 균형 트리이기 때문에 삽입의 시간복잡도는 O(lg N)입니다.

삽입은 이정도면 괜찮은 것 같고, 최솟값의 확인은 더 간단합니다. 그냥 루트에 적힌 값이 최솟값입니다. 단 주의하셔야 하는게, 최소 힙에서는 최솟값을 효율적으로 확인할 수 있지만 열 번째로 작은 값의 확인이라던가 최댓값의 확인은 모든 원소를 다 보는게 아닌 한 불가능합니다. 반대로 최대 힙이었다면 루트에 최댓값이 적혀 있으니 최댓값의 확인은 가능하지만 열 번째로 큰 값의 확인이라던가 최솟값의 확인은 마찬가지로 불가능합니다. 이 점 또한 이진 검색 트리와 힙의 차이라고 볼 수 있겠습니다.

마지막으로 최솟값을 지우는 연산인데, 여기서 최솟값인 루트 8을 지우고 싶습니다. 그런데 그냥 무턱대고 지웠다가는 트리 구조가 깨질테니 뭔가 방법을 생각해야 합니다.

그 방법은 뭐냐면, 트리 구조 상에서 가장 마지막 위치인 52와 8의 자리를 바꾸고 8을 제거해요. 그러면 일단 어찌됐든 8의 자식이 없으니까 트리의 구조는 잘 유지가 됩니다.

그런데 52가 루트로 오면 부모가 자식보다 작다는 조건이 다 꼬였습니다. 원래 52가 12보다도 작고 13보다도 작아야 하는데 지금은 전혀 그렇지가 않습니다. 그래서 뭔가 조치가 필요합니다.
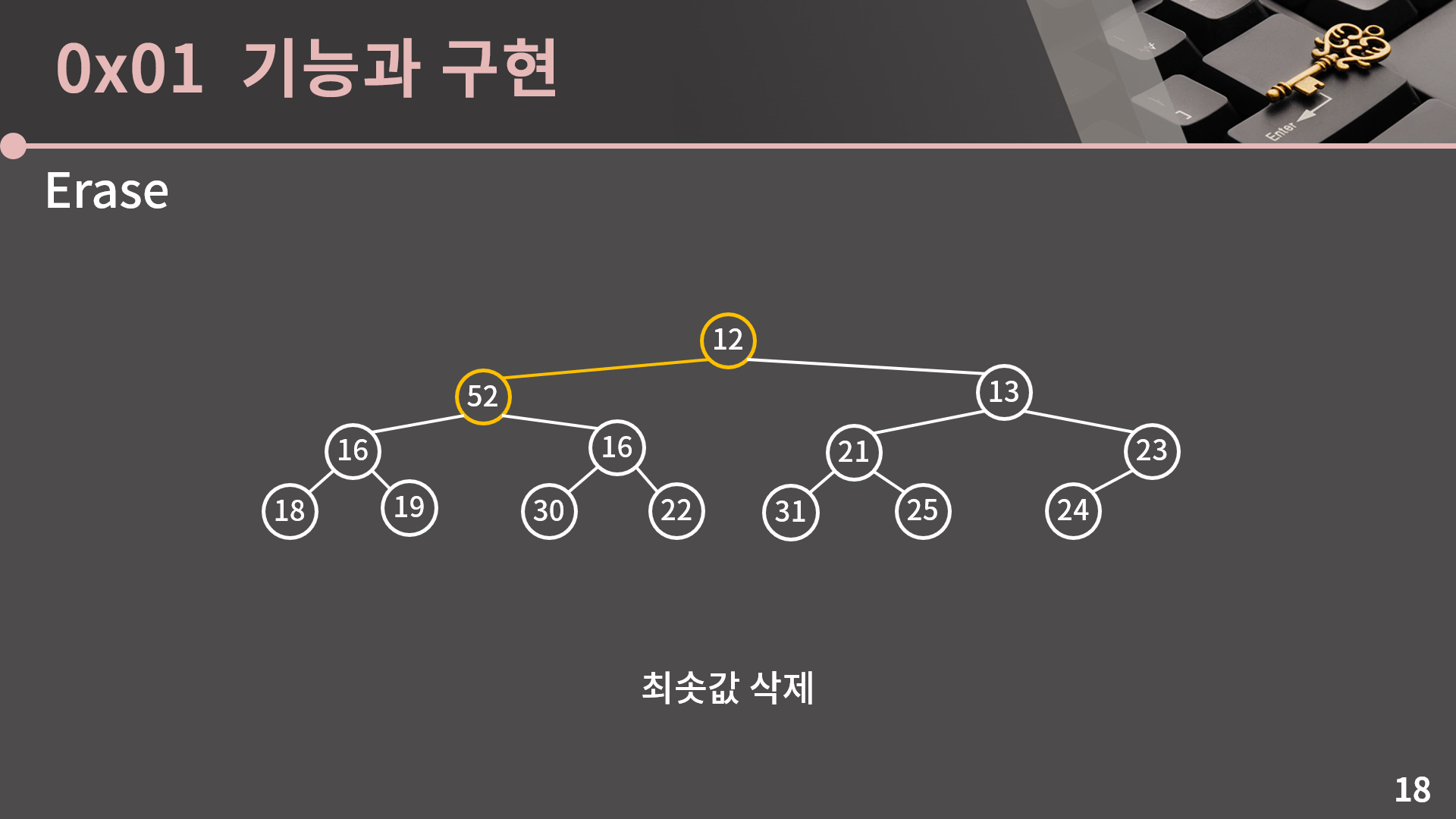
삽입에서 처리한거랑 비슷하게 내부적으로 자리를 바꿔서 해결을 하고 싶은데, 셋 중에 가장 작은 원소가 부모로 가야하는건 좀 당연해보여요. 그래서 셋 중에서 최솟값인 12가 부모로 가야 하고, 12와 52의 자리를 바꿨습니다.
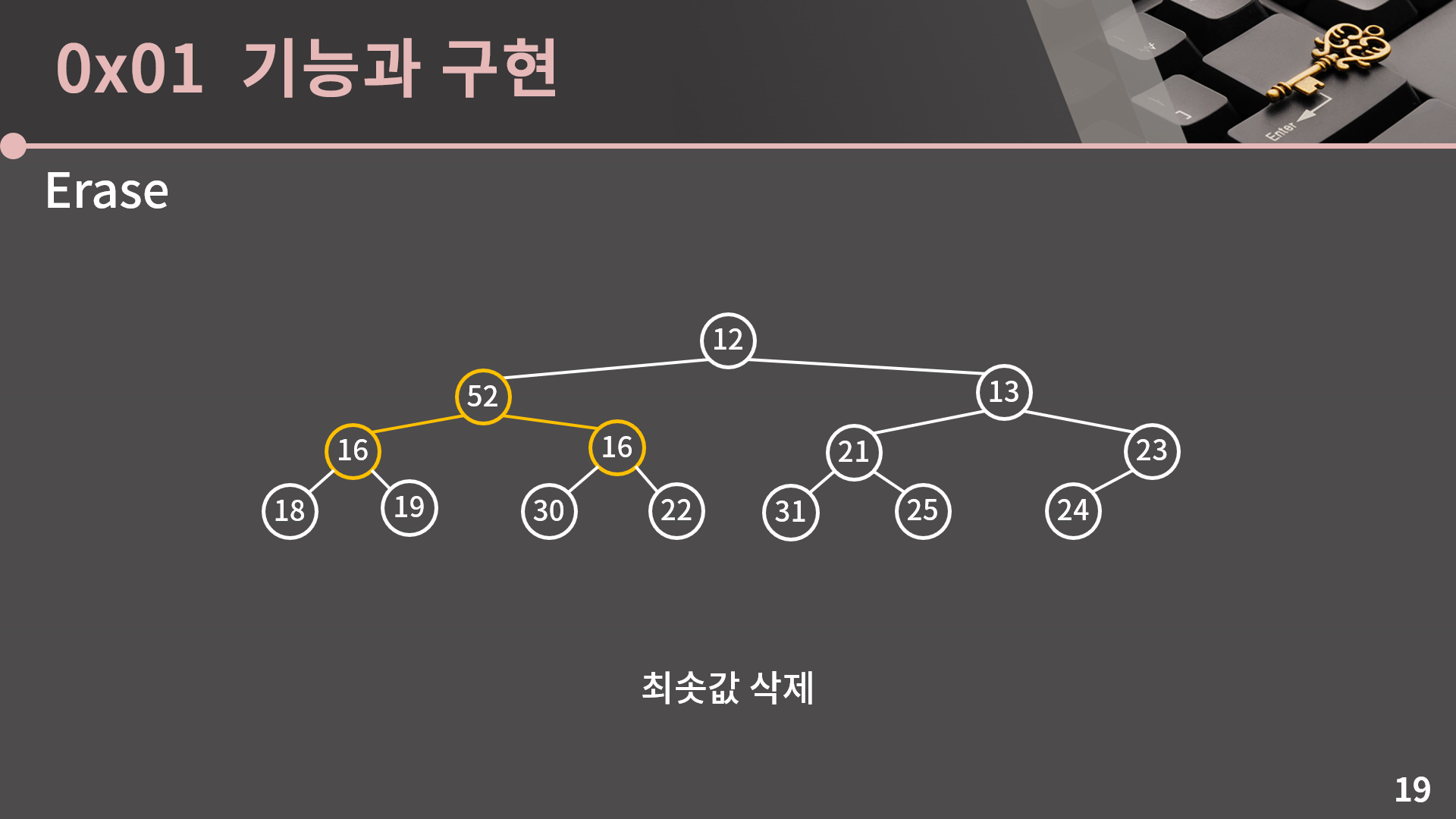
그리고 여기서 끝이 아니고 52, 16, 16에서 또 문제가 발생했습니다. 또 비슷한 논리 흐름으로 16을 52의 자리로 올려야 합니다. 이렇게 둘의 값이 같을 때에는 둘 중 어느 것을 올리더라도 문제가 없습니다.

오른쪽에 있던 16과 값을 바꿨고, 52, 30, 22에서 또 최소 힙의 성질이 위배됐습니다. 이걸 어떻게 처리해야 할지는 잘 아실거라 믿습니다.
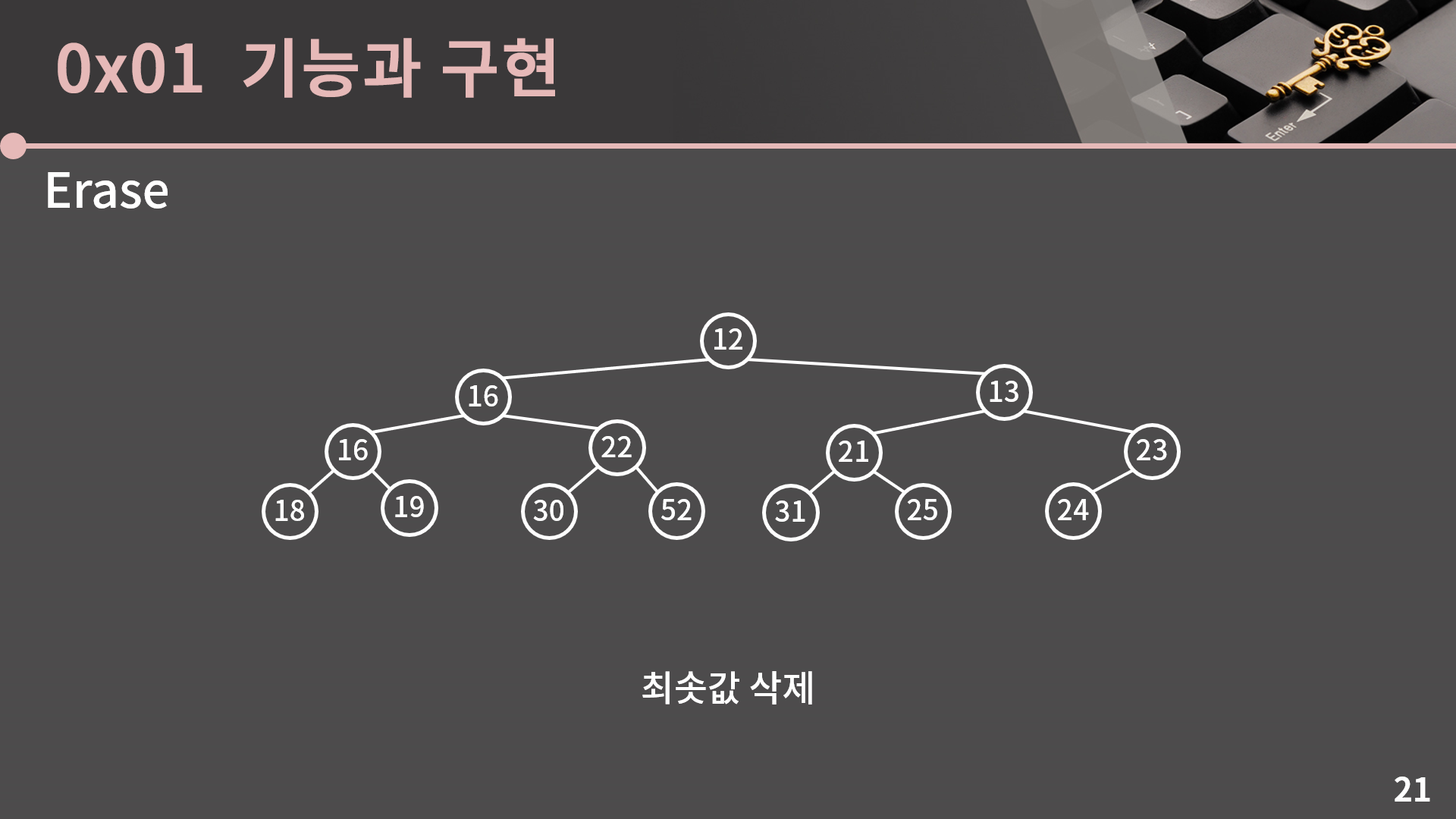
52와 22의 자리를 바꿔주면 끝납니다. 이렇게 일단 트리 구조 상에서 가장 마지막 위치인 값과 루트를 바꿔서 루트를 안전하게 제거하고, 이후 힙의 성질이 잘 만족될 수 있게 내부적으로 위치를 바꾸는 방식으로 삭제를 구현할 수 있습니다. 이해를 잘 했나 확인하는 차원에서 삭제를 한 번 더 진행해보겠습니다. 직접 손으로 해보시고 결과가 저랑 같은지 확인해보시는걸 추천드립니다.

먼저 트리 구조 상에서 가장 마지막 위치인 24와 루트인 12의 자리를 바꿉니다.
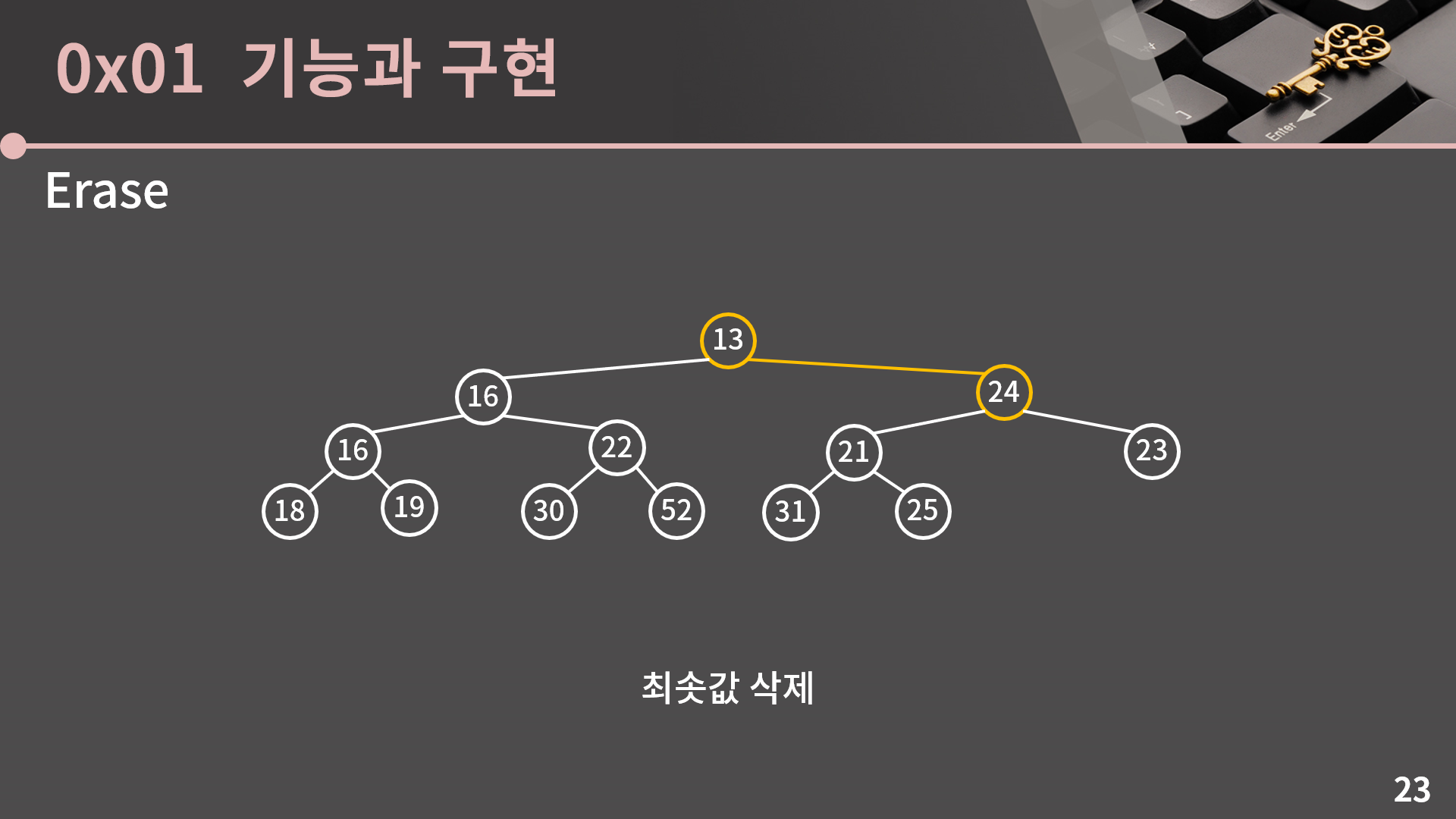
그 다음으로 24, 16, 13에서 최소 힙의 성질이 위배됐기 때문에 13과 24의 자리를 바꿔줍니다.
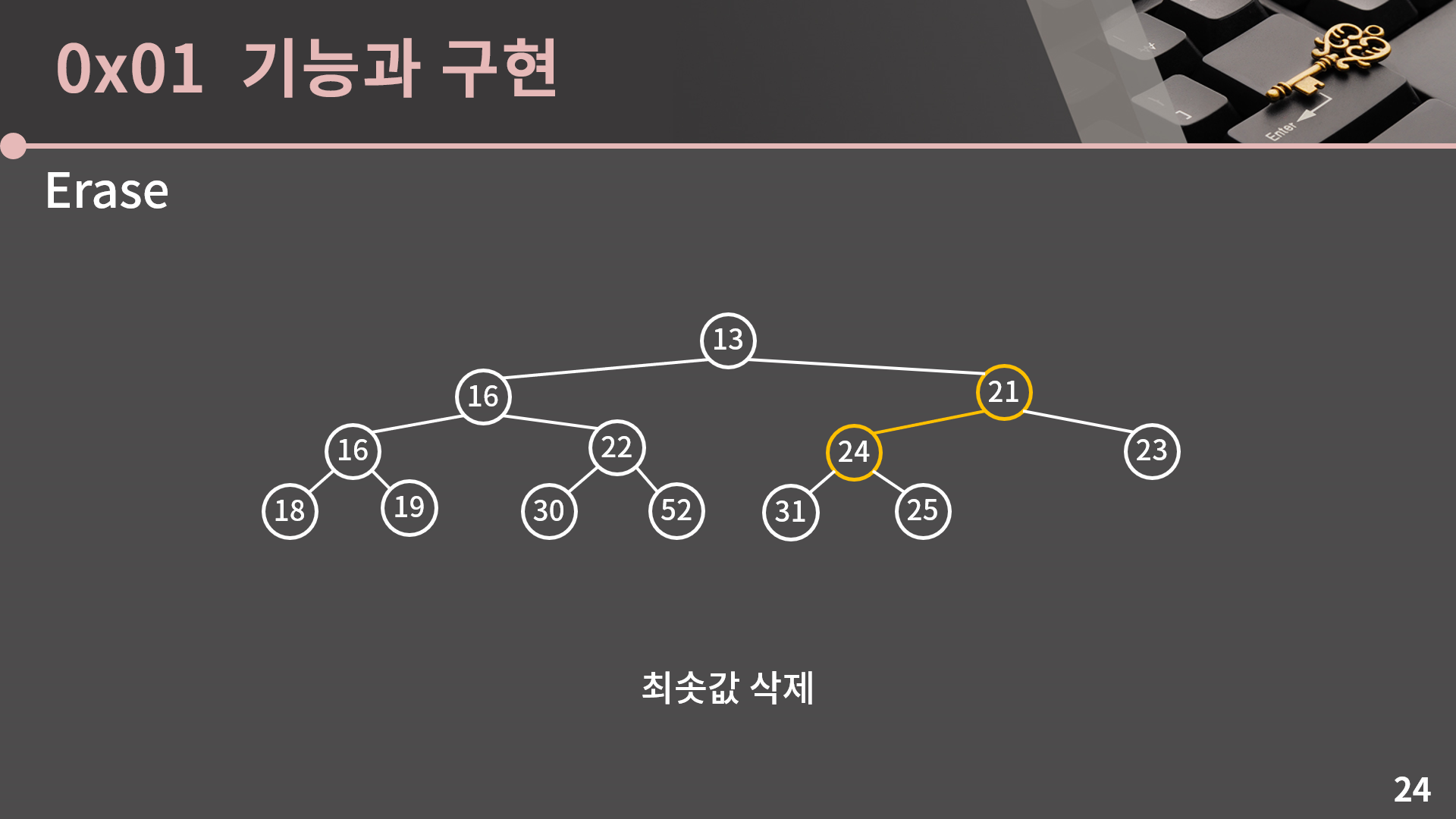
그 다음으로는 24, 21, 23에서 최소 힙의 성질이 위배됐기 때문에 21과 24의 자리를 바꿔줍니다.
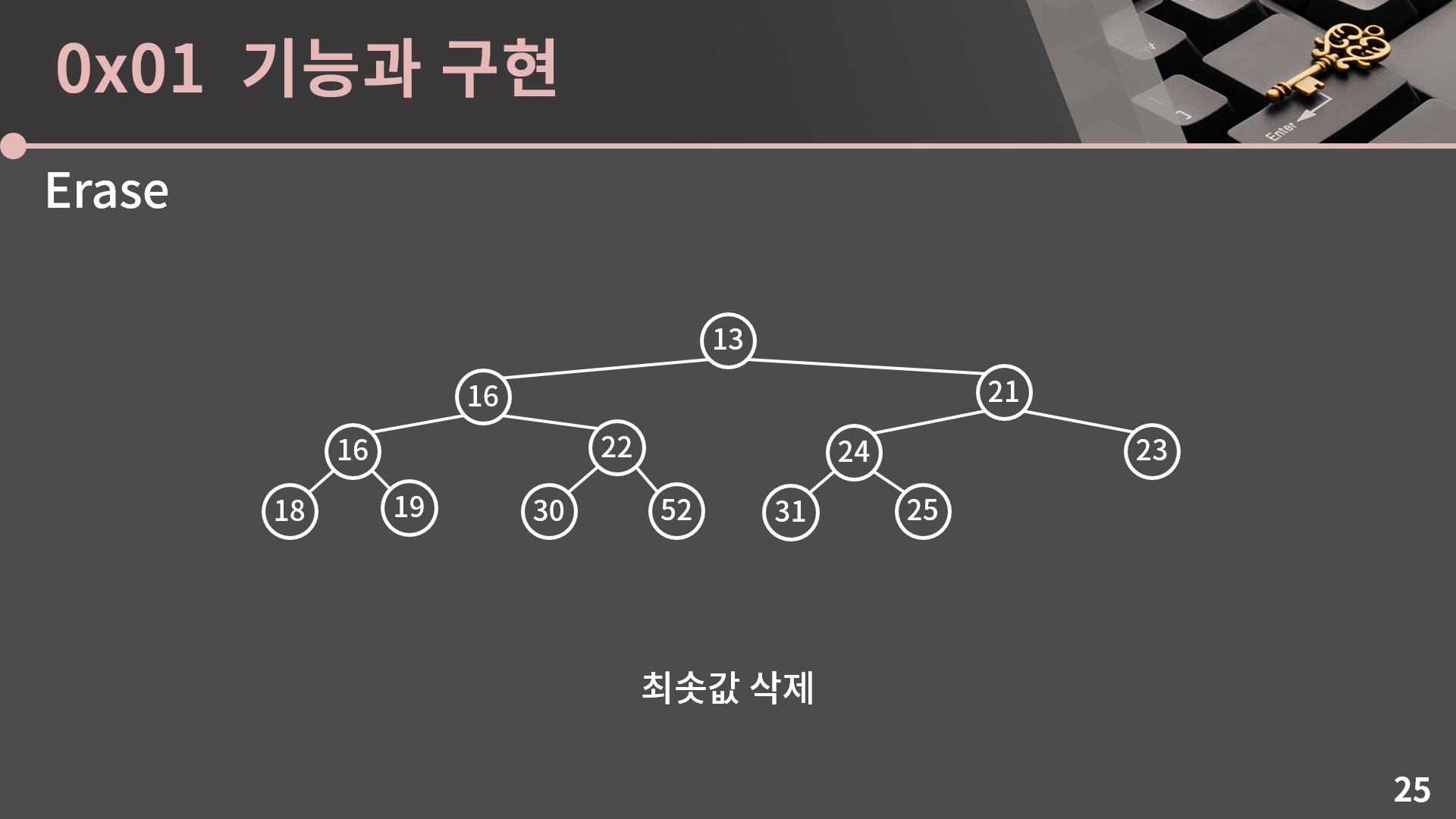
24가 내려간 후 24, 31, 25에서는 최소 힙의 성질이 잘 맞습니다. 이렇게 되면 더 내려갈 필요 없이 과정을 여기서 종료할 수 있습니다.
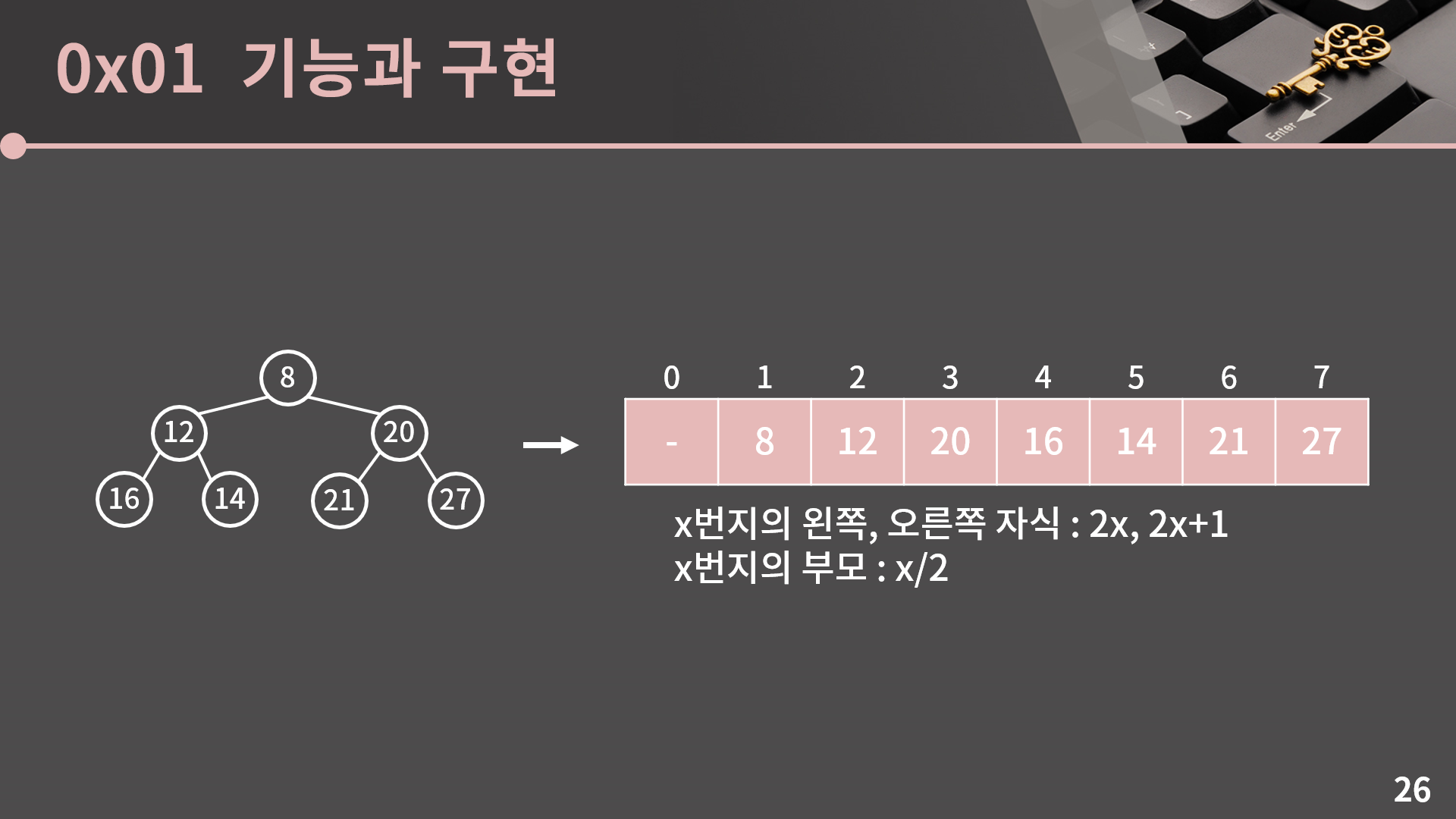
이렇게 이해한 방법을 바탕으로 구현을 해보려고 해요. 그런데 지금 저희는 이진 트리 구조를 어떻게 코드로 표현해야 하는지 자체를 모르고 있습니다. 일반적인 이진 트리 구조를 코드로 표현하는 방법은 나중에 트리 단원에서 배울거긴 한데 지금 이 힙에 한해서는 각 원소를 배열로 대응시켜 다소 간단하게 나타낼 수 있습니다. 이 표를 보시면 조금 와닿을 것 같은데, 힙에서 삽입하는 위치의 순서가 8, 12, 20, 16, 14, 21, 27입니다. 이 순서대로 번호를 1, 2, 3, 4, 5, 6, 7 이렇게 붙여서 배열에 넣습니다. 사실 0번지부터 넣어도 크게 상관은 없는데 저는 그냥 1번지부터 넣었습니다. 이렇게 넣으면 x번지의 왼쪽, 오른쪽 자식은 각각 2x, 2x+1번지고 x번지의 부모는 x/2번지입니다. 예를 들어 3번지인 20의 부모는 3/2 = 1번지인 8이고 왼쪽과 오른쪽 자식은 각각 2*3 = 6번지인 21과 2*3+1 = 7번지인 27입니다.
여기서 돌발 퀴즈를 하나 내보자면, 앞 단원에서 배운 이진 검색 트리도 이렇게 배열 하나에 표현을 할 수 있었을 것 같습니다. 그냥 비슷하게 번호를 붙여서 배열에 쓰면 될텐데 왜 그렇게 안했을까요? 이진 검색 트리는 이렇게 번호를 붙여서 배열로 나타낼 수 없는 아주 중요한 이유가 있습니다. 한 번 임의의 이진 검색 트리를 그리고 그걸 직접 손으로 배열로 표현했을 때 뭔가 조금 어색한 점이 있나, 그 어색한 점을 극대화하는 이진 검색 트리 구조가 있나, 또 과연 어찌저찌 배열로 나타냈다고 쳤을 때 이진 검색 트리에서 각종 연산을 수행한다면 시간복잡도가 어떻게 되는가 그런걸 고민해보시면 답을 찾을 수 있습니다. 그냥 지금 제가 바로 알려드리면 재미가 없으니까 충분히 고민을 해보시고, 제가 지금 이 강의 내에서 답을 바로 알려드리지는 않으려고 합니다. 당장 답이 잘 안떠오르더라도 깊게 고민을 해보면 답을 알 수 있다고 생각하는데 몇 날 며칠을 고민해도 전혀 감이 안오면 아마 블로그 댓글이나 유튜브 댓글에 누군가는 답을 써놓을테니 그걸 참고하도록 합시다.

앞에서 소개한 배열을 바탕으로 삽입, 최솟값 확인, 최솟값 삭제 기능을 제공하는 최소 힙을 만들어보려고 합니다. 그렇게 막 어려울 것 같지는 않으니 자신감을 가지시고 제가 스켈레톤 코드를 드릴테니 안의 내용을 채워보도록 합시다. 그리고 마침 BOJ 1927번: 최소 힙 문제가 대놓고 최소 힙을 구현할 것을 요구하는 문제여서 내용을 채워넣은 후에는 저 문제에 제출을 해보셔서 제대로 짰는지 확인할 수도 있습니다.
코드에서 push 함수는 값을 넣는 함수, top 함수는 최솟값을 반환하는 함수, pop 함수는 최솟값을 제거하는 함수입니다. 작성을 다 한 다음에는 test 함수로 간단하게 잘 동작하는지 확인해볼 수도 있습니다. 조금 막막할 수 있겠지만 말했다시피 먼저 x번지의 부모는 x/2번지이고 왼쪽과 오른쪽의 자식은 각각 2x, 2x+1번지라는걸 참고하면 삽입과 삭제에서 저희가 본 그 상황을 구현할 수 있습니다. push는 먼저 sz를 참고하면 어디에 값을 넣어야 하는지 알 수 있고 이후 대소관계에 따라 값을 적절하게 바꿔주면 됩니다. top은 그냥 너무 간단하고 pop은 마지막 위치인 sz번지의 값을 1번지에 우선 넣고, 마찬가지로 대소관계를 잘 따지면서 필요에 따라 값을 자식으로 내리면 됩니다. 다음 슬라이드부터 코드가 바로 나오니 코드를 보기 전에 먼저 직접 한 번 시도해보도록 합시다.

먼저 push 함수부터 보겠습니다. 현재 힙에 sz개의 원소가 들어있으니 heap[sz+1]에 x를 넣고 sz를 1 증가시켜야 하는데 그걸 02번째 줄처럼 썼습니다. 일단 자리에 넣은 후에는 계속 부모로 올라가면서 값을 잘 바꿔주면 됩니다. 크게 코드에서 이해가 안될 부분은 없어보여서 넘어가겠습니다.

top 함수는 더 날먹인데 그냥 루트가 1번이니까 heap[1]을 반환하면 끝입니다.

마지막으로 이 pop 함수는 사실 처음 구현하면 조금 이것보다 비효율적인 형태로 구현을 하기가 쉽습니다. 일단 기본적으로는 heap[1]에 heap[sz]를 넣고 sz를 1 감소시키면 알아서 루트의 제거는 처리가 되고, 이후 최소 힙의 성질을 잘 만족할 수 있게 대소관계에 따라 값을 잘 바꿔야 합니다. 실제 구현을 할 때 굉장히 조심을 해야 하는 점 몇개를 보면 먼저 현재 보고 있는 인덱스가 이미 리프에 도달했는지를 꼭 확인해서 리프에 도달했다면 중단해야 합니다. 그건 05번째 줄의 코드와 같이 왼쪽 자식이 sz보다 큰지를 통해 확인할 수 있습니다. 그리고 리프가 아니라면 왼쪽 자식은 항상 있겠지만 오른쪽 자식은 없을 수도 있습니다. 제 코드를 보시면 알겠지만 저는 일단 왼쪽 자식과 오른쪽 자식 중에서 작은 값을 min_child에 담고 그 값이 idx보다 작은지를 확인하는 방식으로 구현했습니다. 그리고 이 때 오른쪽 자식이 없는 경우를 잘 처리하기 위해서 08번째 줄과 같이 rc <= sz인지를 먼저 검사해줬습니다.
아마 직접 짰다면 제가 말한 저 조심해야 하는 점을 놓쳐서 런타임 에러가 나거나 왼쪽 자식이 오른쪽 자식보다 작을 때, 오른쪽 자식이 왼쪽 자식보다 작을 때 이런 식으로 조건문을 써서 코드가 조금 길어지거나 하는 일이 발생할 수 있긴 합니다. 그럼에도 불구하고 직접 시도를 해보는게 중요한거니까 혹시 완성을 해내셨다면 스스로에게 좀 뿌듯함을 느끼시고, 제 코드를 참고해서 좋은 점은 흡수해가면 됩니다. 세 함수를 모아둔 코드는 여기에서 확인할 수 있습니다.

사실 예상하셨겠지만 STL에 우선순위 큐가 있어서 사실 우리는 그냥 이걸 쓰면 되긴 합니다. 애초에 직접 힙을 구현할 때 STL에 있는 멤버 함수의 이름에 맞춰서 push, pop, top 등의 이름을 그대로 썼고 또 STL queue와 멤버 함수 이름이 같기도 해서 금방 친숙해질 수 있습니다. 단 priority_queue를 그냥 선언하면 기본적으로 최대 힙입니다. 만약 최소 힙이 필요하다면 06번째 줄과 같이 선언을 해야 합니다. 보면 진짜 안 친숙합니다. 2번째 인자로는 vector<int>를 줘야하고 3번째 인자로는 functional 헤더에 정의되어 있는 greater라는 함수를 넘겨줘야 합니다. 2번째 인자에 대한 설명은 생략하고, 3번째 인자에 대한 설명만 간략하게 해볼게요. 조금 많이 이전 내용이라 가물가물할 수도 있지만 0x0F강에서 비교 함수를 만들어 정렬을 수행하는 방법에 대해 다뤘었습니다. 그리고 STL 중에서 수의 대소 관계가 필요한 set, multiset, map, priority_queue 등에서도 마찬가지로 비교 함수를 인자로 줄 수 있습니다. 기본적으로 priority_queue는 최대 힙인데 greater<int>를 인자로 주면 대소관계가 뒤집혀서 최소 힙으로 쓸 수 있습니다. 비슷한 맥락에서 생각하면 아예 다른 비교 함수를 넘겨줄 수도 있습니다.

그런데 이번 강의의 내용을 보다가 혹시 이런 의문이 든 분 없을까요? 지금 최댓값 혹은 최솟값을 빼고, 원소 추가하고 이런건 set에서 다 할 수 있는 연산입니다. 또 시간복잡도도 어차피 O(lg N)으로 다 똑같습니다. 그러면 set에서 제공하는 기능이 훨씬 더 많은데 그냥 set을 쓰면 되지 굳이 priority_queue를 써야할 상황이 있을까요? 이 질문에 대해 어떻게 답을 하면 깔끔할까요?

일단 맞는 말이에요. 빅오의 관점에서 시간복잡도가 똑같고 set의 기능이 더 다양합니다. 맞는 말인데, priority_queue는 set보다 수행 속도가 빠르고 공간도 적게 차지합니다. set은 전 단원에서도 언급했지만 새 정점을 동적할당하거나 정점을 제거하고 불균형이 발생했을 때 그것에 대한 처리가 필요하기 때문에 O(lg N)이라도 꽤 시간을 많이 차지합니다. 반면 priority_queue는 트리 자체가 불균형이 없고 무조건 lg N번 비교하면서 자리를 바꾸면 끝이라 훨씬 빠릅니다. 같은 연산을 할 때 set과 priority_queue는 속도가 한 2-4배 정도 차이날 수 있습니다. 그리고 공간을 차지하는 정도도 차이가 많이 납니다. 그렇기 때문에 priority_queue에서 제공하는 연산들만 필요할 경우에는 set을 쓰는 것 보다 priority_queue를 쓰는게 좋습니다.

이제 연습 문제만 남았습니다. 먼저 BOJ 11286번: 절댓값 힙 문제를 보겠습니다. 문제를 보면 그냥 사실 대놓고 힙을 쓰라는 문제이고 직접 구현한 힙을 이용해도 되지만 그냥 STL을 써보겠습니다. 이 비교 함수가 좀 오랜만에 등장을 했으니 좀 가물가물할 수도 있을 것 같습니다. 그래서 설명을 다시 드리면 비교 함수 이름을 cmp라고 할 때 cmp(앞에 위치해야 하는 원소, 뒤에 위치해야 하는 원소) = true가 되어야 합니다. 그리고 STL priority_queue는 최대 힙, 즉 가장 뒤의 원소를 높은 우선순위로 두는 STL이기 때문에 cmp 함수를 잘 설정해야 합니다. 예를 들어서 이 절댓값 힙에 값이 여러개 있다면 -1이 그 중에서 가장 우선순위가 높은 값입니다. 그러면 cmp(다른 값, -1) = true가 되도록 cmp를 잘 짜야 합니다. 그리고 cmp(a, a)는 꼭 false여야 합니다. 이게 만족되지 않으면 런타임에러가 날 수 있습니다. 나중에도 STL priority_queue에다가 비교 함수를 어떻게 둬야하나 헷갈리기 쉬운데 priority_queue가 기본적으로 최대 힙이라는걸 꼭 기억하셔야 합니다. 다행히 이 문제의 경우에는 비교 함수만 잘 채워놓고 나면 그냥 시킨대로 짜면 끝이라 크게 걱정할게 없습니다.
그런데 sort 함수에서는 그냥 외부에 함수를 잡고 그 이름을 3번째 인자로 주면 끝인데 priority_queue에서는 조금 다릅니다. 직접 구글에 cpp priority queue custom compare라고 검색해서 해결을 하셔도 되고 아니면 그냥 제 코드를 보고 계속 진행을 해보셔도 됩니다.

사실 놀랍게도 지금까지 제가 우선순위 큐에서 임의로 만든 비교 함수를 쓴 적이 한 번도 없었습니다. 이 문제를 4년 반쯤 전에 풀었길래 어떤 식으로 풀었나 봤더니 그 땐 STL을 안 쓰고 그냥 힙을 직접 구현해서 풀었습니다. 그래서 사실 저도 이번에 자료를 만들다가 안건데 priority_queue에서 비교 함수를 사용할 때에는 지금 코드의 04-10번째 줄에 있는 것 처럼 클래스를 만들어서 사용을 해야 합니다. 그냥 sort 함수에서 하던 것 처럼 그냥 외부에 bool cmp를 선언한 다음에 priority_queue<int, vector<int>, cmp> pq; 이렇게 선언을 하면 오류가 났습니다. 그냥 원래 이런거다 그냥 외워라 이런 설명을 안좋아하긴 하는데 이 강의 안에서는 cpp 얘기를 좀 많이 건너뛰었다보니까 이유가 뭔지 더 자세하게 짚고 가긴 힘듭니다. 왜 저런건지 정말 궁금해서 나는 무조건 이해를 하고 갈거다 하시는 분은 일단 sort는 함수인데 priority_queue는 컨테이너인걸 먼저 인지하신 상태로 한번 공식 레퍼런스 문서를 들여다보시면 이해에 도움이 될 수 있을 것 같습니다. 그래서 저 사용법은 그냥 아쉽지만 원래 그런건가보다 하고 좋게 좋게 넘어가기로 하겠습니다.
비교 함수를 보면 일단 절댓값이 다르다면 그냥 앞에 있는 수의 절댓값이 뒤의 수보다 크면 true를 반환하면 됩니다. 만약 절댓값이 같다면 두 수가 다르고 앞이 양수, 뒤가 음수일 때에만 true를 반환해야 하니 08번째 줄과 같은 조건이 들어갑니다. 다시 한 번 강조하지만 비교 함수의 두 인자로 같은 값이 들어가면 반드시 false를 반환해야 합니다. 예를 들어서 cmp(-2, -2)는 false여야 합니다. 이 비교 함수의 개념이 생소하면 이 강의가 끝나고 다시 0x0F강 - 정렬 II 단원을 확인해보도록 합시다.
비교 함수만 잘 정의해두고 나면 그 다음은 크게 어려울 게 없습니다. vector나 stack이나 set이나 그 외 온갖 STL에서 다 그랬었지만 비어있는데 top을 확인한다거나 pop을 한다거나 하면 바로 런타임에러 직행이기 때문에 21번째 줄처럼 먼저 empty인지 확인하고 empty가 아닐 때에만 top을 출력하고 pop을 해야한다는 것만 조심하시면 크게 어려울 것 없는 문제였습니다. (정답 코드)

두 번째 문제는 1715번: 카드 정렬하기 문제입니다. 이 문제도 그리디한 접근이 필요한데 일단 정당성 증명은 버리고 그냥 그럴싸한 방법을 고민해보도록 합시다. 방법만 떠올려본 다음에 제 설명을 확인해보셔도 괜찮고, 아니면 아예 구현까지 직접 해본 후에 제출을 해서 내 풀이가 정말 맞는지 확인을 해보셔도 괜찮습니다. 살짝 야매일수도 있는 힌트를 드리자면 지금 단원이 우선순위 큐니까 뭔가 떠올린 그리디 풀이에서 우선순위 큐가 쓰여야 한다는걸 눈치챌 수 있습니다.
풀이를 바로 설명을 드리면 다 합쳐질 때 까지 매 순간마다 가장 작은 묶음 2개를 하나로 만드는걸 반복하면 됩니다. 진짜 그냥 대충 생각했을 때 먼저 합쳐진 애들이 비교를 많이 하게 될테니 막 그렇게 근본 없는 풀이는 아닌데 왜 진짜 이런 그리디 풀이가 되는지를 우리는 생각을 해봐야 합니다. 제 생각에 지금 설명할걸 최소 들어본 분은 여럿 계실 것 같긴 한데 아마 이 문제와 연관을 못짓고 있을 것 같습니다. 정보 이론(Information theory)이라는 분야에서 되게 유명한 알고리즘과 지금 이 문제가 닿아있습니다.
허프만 코딩이라고 데이터를 효율적으로 압축할 때 사용하는 방법이 있습니다. 우리 흔히 압축이라고 하면 떠오르는 zip이나 rar같은 그런 파일들을 압축할 때 이 허프만 코딩이 쓰입니다. 그리고 그 허프만 코딩에서 압축을 지금 이 문제의 그리디 풀이와 완전 똑같은 방식으로 합니다. 그렇다고 해서 허프만 코딩을 꼭 알아야 한다 그런건 아니고, 그냥 알아두면 쓸데 있을지도 모르는 신비한 잡지식이라고 치겠습니다. 아무튼 허프만 코딩이 최적임을 증명하는 과정을 보면 귀납법을 이용합니다. N = 2면 저희의 방법이 최적인건 자명하고, N = k이면 최적이라고 할 때 N = k+1에서도 최적임을 보이는 방식으로 증명이 가능한데 아쉽지만 디테일은 생략하겠습니다. 그래서 아무튼 허프만 코딩을 이전에 배운 적이 있다면 아 이 문제에서의 그리디 풀이가 그냥 대놓고 허프만 코딩에서의 방법이랑 똑같구나 하고 이해하시면 되겠고, 허프만 코딩을 처음 들어보셨다면 굳이 허프만 코딩을 찾아보실 필요는 없고 뭔가 이렇게 합쳐나갈 때 작은 것 부터 처리하는 그리디 풀이가 성립하는구나 정도로만 생각하고 넘어가겠습니다.
이제 이 풀이대로 구현을 할건데 매번 작은 원소 2개를 빼고 걔네 합을 힙에 추가해야 하니까 최소 힙이 필요하겠죠? 구현을 바로 해보겠습니다.

코드를 보면 07번째 줄과 같이 힙을 최소 힙으로 선언을 했고, 매 순간마다 최솟값 2개를 뺀 후 둘의 합을 ans에 더하고 또 우선순위 큐에 추가했습니다. 사실 답이 int 범위 안에 들어오는지 확신을 하기가 어렵습니다. 그래서 맨 처음에는 ans의 자료형을 long long으로 둬서 제출했었는데 답이 가장 클 경우, 그러니까 카드 묶음이 10만개이고 값이 전부 1000인 경우를 돌려봤더니 답이 int 범위 안에 들어오는걸 확인했습니다. 그래서 그 후에 ans의 자료형을 int로 고쳤는데 혹시 여러분 중에 답의 범위를 고민하지 않고 그냥 int로 둬서 푼 분이 계시다면 자료형을 꼭 따져볼 필요가 있다는걸 늘 인지하도록 합시다. (정답 코드)

이렇게 우선순위 큐가 마무리됩니다. 굉장히 당연한 얘기일 수도 있지만 힙을 이용하면 N개의 원소를 삽입했다가 크기 순으로 빼는 방식으로 O(NlgN)에 N개의 원소를 정렬할 수 있습니다. 비록 정렬 단원에서는 아직 힙을 배우기 전이어서 힙 정렬을 소개해드리지 않았지만 힙을 배운 지금은 힙 정렬의 동작을 쉽게 이해할 수 있을 것 같습니다. 또 우선순위 큐는 엄청 특별한 응용 사례가 있다기 보다는 우선순위 큐에서 제공하는 기능이 곧이곧대로 필요한 상황이 있을 때 편하게 가져다 쓴다고 생각을 하면 됩니다. 그리고 무엇보다도 몇 단원 뒤에 배우게 될 다익스트라 알고리즘에서 우선순위 큐가 쓰이기 때문에 힙의 동작 원리를 아는 것도 중요하고 무엇보다도 STL을 좀 자유자재로 쓸 수 있는 연습을 해두시면 분명 도움이 됩니다. 그러면 다음 시간에 만납시다.
'강좌 > 실전 알고리즘' 카테고리의 다른 글
| [실전 알고리즘] 0x1A강 - 위상 정렬 (12) | 2021.12.27 |
|---|---|
| [실전 알고리즘] 0x19강 - 트리 (25) | 2021.12.14 |
| [실전 알고리즘] 0x18강 - 그래프 (31) | 2021.12.01 |
| [실전 알고리즘] 0x16강 - 이진 검색 트리 (35) | 2021.11.06 |
| [실전 알고리즘] 0x15강 - 해시 (38) | 2021.09.27 |
| [실전 알고리즘] 0x14강 - 투 포인터 (40) | 2021.08.20 |