
안녕하세요, 바킹독입니다.. 저번 단원의 내용인 코드 작성 요령 II는 순한 맛이었는데 오늘건 그냥 단맛입니다. 난이도가 굉장히 낮으니 긴장 푸시고 강의로 들어가겠습니다.

목차는 따로 설명할게 없습니다.
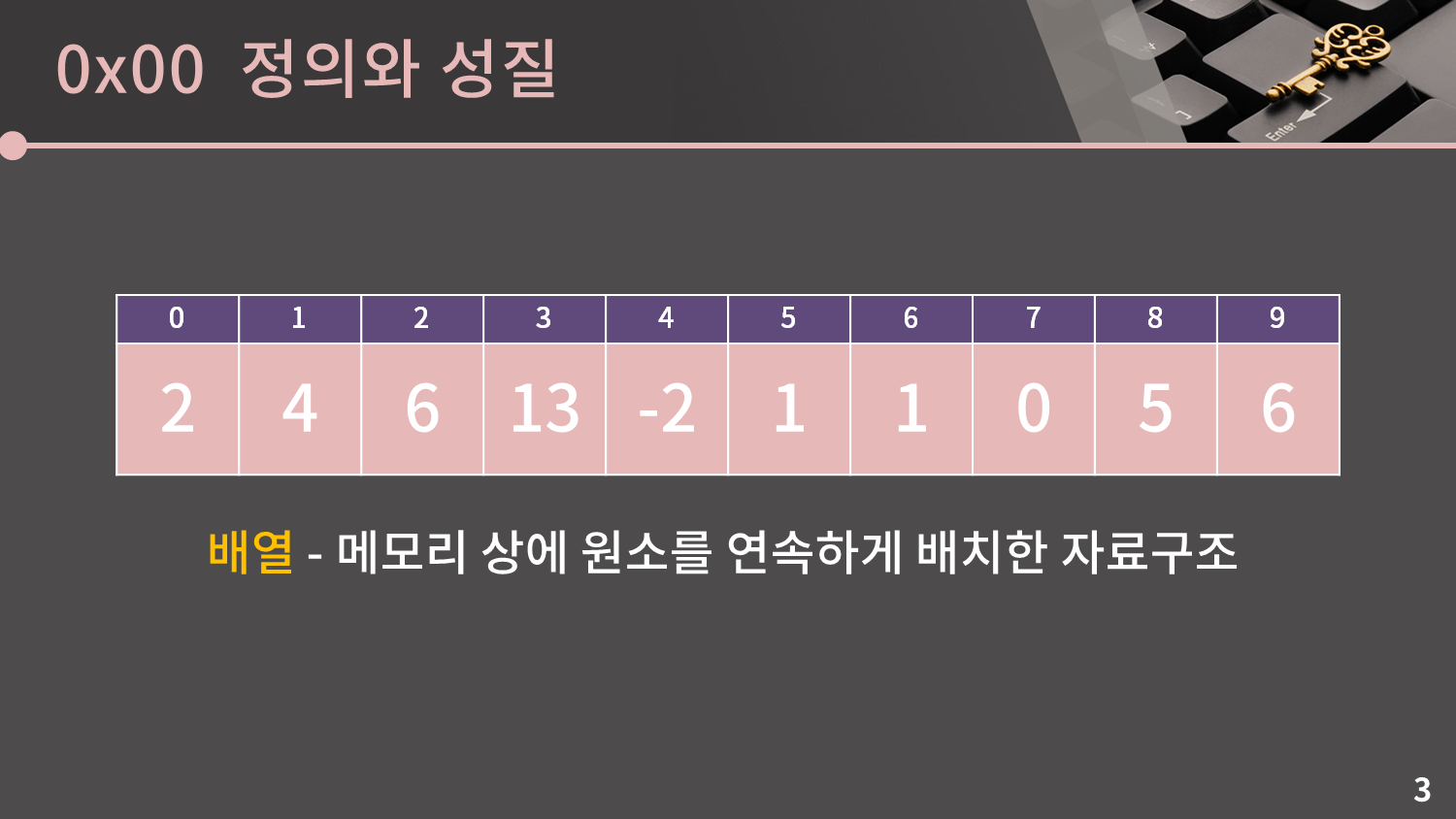
그럼 이제 찐으로 강의를 시작하겠습니다. 이미 배열은 충분히 익숙하실테지만, 저희는 지금까지 프로그래밍 언어의 관점에서 배열을 다뤘기 때문에 자료구조로써의 배열을 익힐 필요가 있습니다.
배열은 메모리 상에 원소를 연속하게 배치한 자료구조입니다. 원래 C++에서는 예를 들어 int arr[10]; 으로 배열을 선언한 뒤에는 arr의 길이를 변경하는게 불가능하지만, 자료구조로써의 배열에서는 길이를 마음대로 늘리거나 줄일 수 있다고 생각하겠습니다.

그 다음으로는 배열의 성질을 생각해보겠습니다. 굳이 암기할 필요는 없이 자연스럽게 이해를 하고 받아들이면 됩니다. 그런데 면접을 대비하는 중이라면 어딘가에 적어두고 암기를 하는 것도 괜찮을 것 같습니다.
첫 번째로 배열은 메모리 상에 원소를 연속하게 배치한 자료구조이라서 k번째 원소의 위치를 바로 계산할 수 있게 됩니다. 시작 주소에서 k칸 만큼 오른쪽으로 가면 되기 때문입니다. 그렇기 때문에 k번째 원소를 O(1)에 확인하거나 변경할 수 있습니다.
두 번째로 메모리는 다른 자료구조와 다르게 추가적으로 소모되는 메모리의 양이 거의 없습니다. 아직 다른 자료구조를 배우지 않아서 비교를 할 수가 없는데, 다른 자료구조들을 배우고 나면 지금 이 소리가 무슨 의미인지 알 수 있을 것입니다.
세 번째로 메모리 상에 데이터들이 붙어있으니까 Cache hit rate가 높습니다. 혹시 Cache hit rate가 뭔지 모르시면 강의를 다 보고 찾아보시면 됩니다.
네 번째로 메모리 상에 연속한 구간을 잡아야 하니 할당에서 다소 제약이 있습니다.
특징들을 간략하게 살펴봤는데, 1번 성질은 사실 저희가 너무 당연하게 활용했던 성질이고, 2번, 3번, 4번 성질은 굳이 신경쓰지 않아도 코딩테스트를 칠 때에는 별로 상관이 없습니다.

이제 배열에서 제공되는 연산들을 하나씩 살펴보겠습니다. 첫 번째로 임의의 위치에 있는 원소를 확인하고 변경하는 연산인데, 이건 너무 자명하게 O(1)입니다.
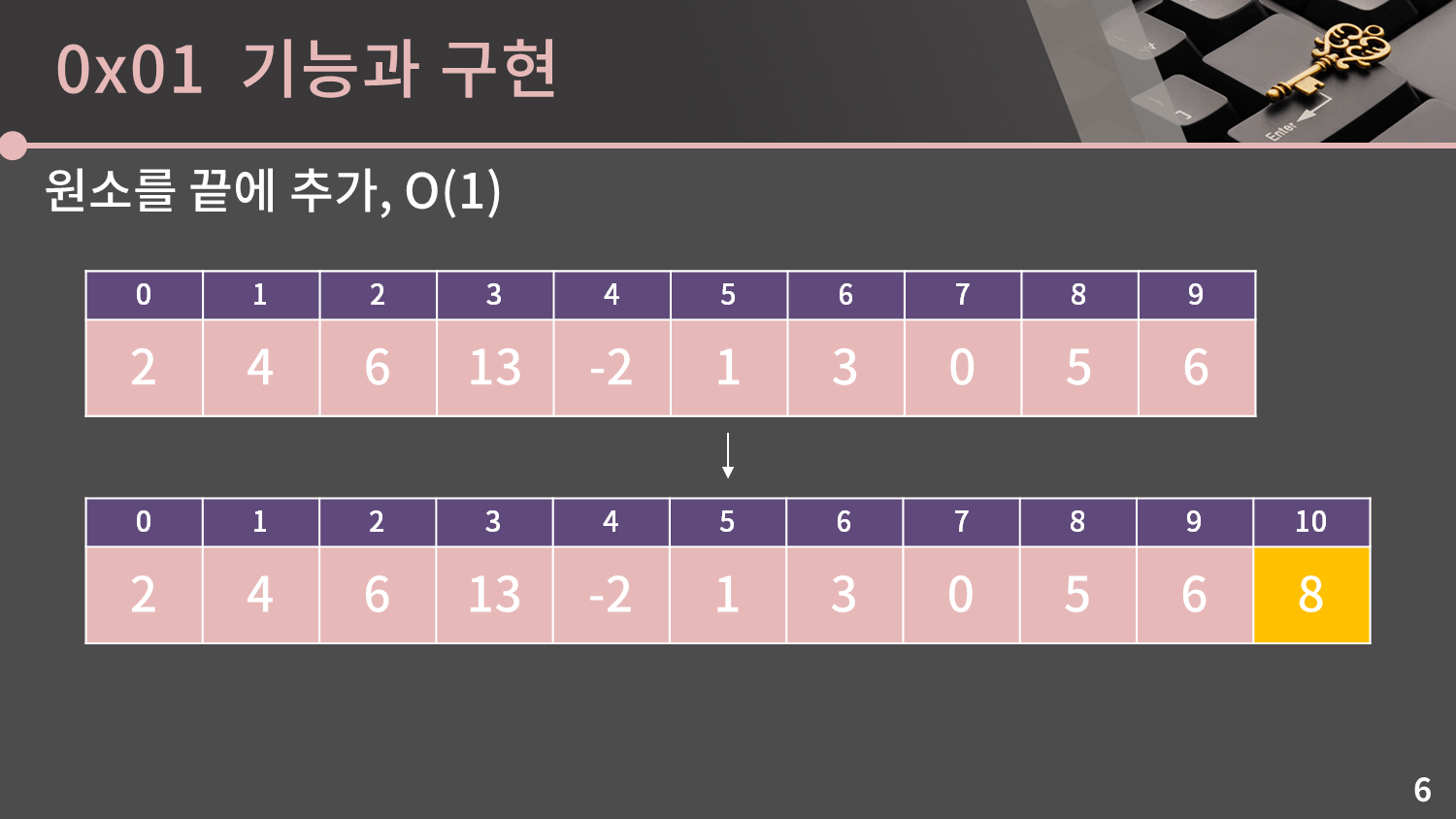
그 다음으로는 원소를 끝에 추가하는 연산인데, 이것도 그냥 끝자리에 값을 쓰고 길이를 1 증가시키면 되니 O(1)입니다.

다음으로 마지막 원소를 제거하는 것도 그냥 길이를 1 줄이면 되니까 O(1)입니다.

여기서부터가 관건인데, 임의의 위치에 원소를 추가하는 과정은 O(N)이 됩니다.
지금 보면 5번에 15를 추가했는데, 이렇게 되면 그 뒤의 원소들을 전부 한 칸씩 밀어야해서 O(N)이 필요하게 됩니다. 마치 책장에 책이 연속해서 꽂혀있을 때 중간에 책을 넣기 위해서는 나머지 책들을 밀어야하는 것과 같은 상황입니다.
추가하는 위치가 끝에 가까울수록 시간은 줄어들고, 앞에 가까울수록 시간은 늘어날테지만 평균적으로는 N/2개를 밀어야하니 O(N)이라고 해도 상관없습니다.

그리고 임의의 위치에 원소를 제거하는 것도 O(N)이 됩니다. 2번 원소를 지웠다고 치면 그 이후에 있던 모든 원소들을 한 칸씩 땡겨와야해서 그렇습니다. 그냥 다 내버려두고 2번 원소만 비워두면 안되냐고 생각하실수도 있지만 그렇게 되면 더 이상 메모리 상에 원소가 연속해서 존재하지 않기 때문에 배열의 정의에도 위배되고 또 k번째 원소를 O(1)에 찾을 수가 없게 됩니다.

정리하면 임의의 위치에 있는 원소를 확인하거나 변경하는건 O(1)이고, 원소를 끝에 추가하는 것도 O(1)이고, 마지막 원소를 제거하는 것도 O(1)인데 임의의 위치에 원소를 추가하거나 임의 위치의 원소를 제거하는건 O(N)입니다.
이제 각 기능들을 직접 구현해보려고 하는데, 위의 3개는 크게 어려움이 없을 것 같고 임의의 위치에 원소를 추가하는 것과 임의 위치의 원소를 제거하는걸 해볼까 합니다.

두 기능을 함수로 만들거고 함수는 이렇게 생겨있습니다. 갑자기 코드가 훅 들어와서 당황했을 수도 있는데 당황할 필요 없습니다.
insert 함수는 idx번째 위치에 num을 넣는 것입니다. 원래 idx번째와 그 뒤에 있던 원소들은 자연스럽게 한 칸씩 뒤로 이동하게 됩니다.
예를 들어 {10, 50, 40, 30, 70, 20}에서 3번째에 60을 넣는다면 30, 70, 20이 한 칸씩 뒤로 밀려서 {10, 50, 40, 60, 30, 70, 20}이 되는 것입니다. 그리고 이 때 len은 참조자로 보냈으니 insert 함수에서 len 값을 바꾸면 원본의 값이 바뀝니다.
그리고 {10, 50, 40, 60, 30, 70, 20}에서 4번째 원소를 지우면 30이 지워지고 {10, 50, 40, 60, 70, 20}이 됩니다.

이제 함수를 여러분들이 직접 짜보는 시간을 가질 것입니다. github 링크에 들어가서 코드를 받은 후에 insert, erase 함수를 채워봅시다.
앞으로도 긴 코드는 저 깃헙 repository를 통해서 드릴거라 저 URL에 들어갈 일이 많으실 것 같습니다.
다 채운 후에 실행을 해서 나온 결과가 insert_test, erase_test 함수에서 주석으로 달아놓은 결과랑 일치하는지 확인해보세요.
다 잘 짜셨나요? 면대면이 아니니 확인할 길이 없지만 충분히 많은 고민을 거쳐서 코드를 짜보셨다고 믿고 계속 진행을 해보겠습니다.



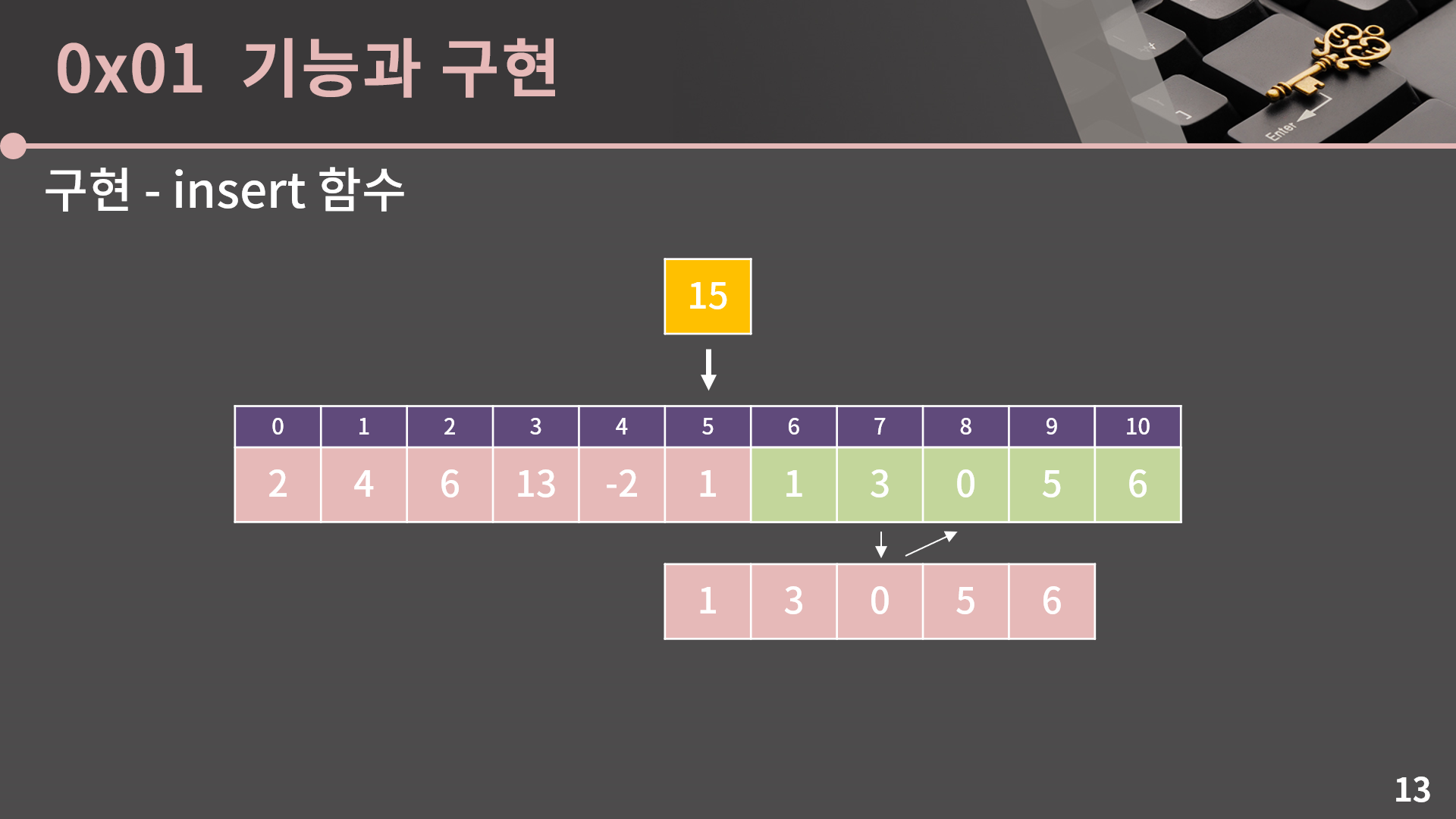

일단 insert 함수부터 살펴보면, 5번째에 15를 넣고싶다고 할 때 1, 3, 0, 5, 6을 오른쪽으로 한 칸씩 밀어서 자리를 만들어줘야 합니다. 그래야 15가 제 자리에 들어갈 수 있기 때문입니다.
그런데 지금 그림으로 나타낼 때에는 원소 5개를 한 번에 옮겼지만. 실제 코드를 짤 때에는 원소를 1개씩 옮길 수 밖에 없습니다.


제일 왼쪽부터 옮긴다고 하면, 1을 6번 자리로 옮기고 났을 때 원래 6번째에 있던 3이 온데간데없이 사라져버렸습니다. 물론 임시 변수나 배열을 만들어서 처리를 할 수도 있겠지만 추가적인 메모리를 쓰지 않고 더 간단한 해결법이 있습니다.







바로 오른쪽에서부터 옮기는 것입니다.

코드를 확인해보시면 오른쪽에서부터 자기 왼쪽의 항을 땡겨오는 것을 볼 수 있습니다. 그런데 만약 02번째 줄에서 i > idx 대신 i >= idx로 작성했다면 어떤 일이 생길까요?
그러면 arr[idx] = arr[idx-1]이 실행되고 04번째 줄에서 arr[idx] = num이 되니 별 문제가 없지 않나 싶겠지만, idx = 0일 때 arr[0] = arr[-1]이라는 명령이 수행됩니다. 그래서 런타임에러가 유발될 수 있습니다.
이외에도 정말 다양한 오답들이 있을 것 같은데, 99%는 인덱스 문제일 것 같습니다. i가 len-1부터인지 len부터인지, 그리고 idx까지인지 idx+1까지인지 뭐 이런 것들이 굉장히 헷갈릴텐데 종이에 구상을 잘 해두고 구현하면 머릿속이 덜 꼬일 것입니다.




그 다음으로는 erase 함수를 구현해보겠습니다. 예를 들어 2번째 원소를 지우고 싶으면 이번에는 3번째부터 9번째까지의 원소들을 왼쪽으로 한 칸씩 밀면 됩니다.









그리고 insert 함수때와 비슷하게 실제 구현을 할 때에는 한 개씩 옮기는데 이번에는 왼쪽부터 처리를 하면 추가적인 메모리를 쓰지 않고 구현할 수 있습니다.

코드는 위와 같습니다.
insert, erase 함수를 메꾼 전체 코드는 같은 디렉토리의 array_test_ans.cpp에서 확인할 수 있습니다.

구현에 대한 부분은 이제 다 됐고, C++에서의 배열은 워낙 간단한 구조여서 특별한 팁은 없는데, 전체를 특정 값으로 초기화시킬 때 어떻게 하면 효율적으로 할 수 있는지만 짚고 넘어가겠습니다.
제일 짤막한건 cstring 헤더에 있는 memset 함수를 활용하는 방식입니다. 그런데 memset 함수는 실수할 여지가 굉장히 많습니다. 예를 들어 0이나 -1이 아닌 다른 값을 넣으면 오동작한다거나, 2차원 이상의 배열을 함수의 인자로 넘겨 그 곳에서 memset을 하면 잘못 들어간다거나 하는 점들이 있습니다. 그래서 memset은 정말 비추천합니다.
두 번째로는 그냥 for문을 돌면서 값을 하나하나 다 바꾸는 방식이고, 코드가 조금 투박하긴 하지만 실수할 여지가 없기 때문에 무난하고 좋습니다.
마지막 방식은 algorithm 헤더의 fill 함수를 이용하는 것이고, fill 함수는 실수할 여지도 별로 없고 코드도 짧으니 익숙해진다면 가장 추천하는 방식입니다.

배열에 대한 이해를 마치고, 이제는 STL vector를 설명해보겠습니다. vector는 배열과 거의 동일한 기능을 수행하는 자료구조로, 배열과 마찬가지로 원소가 메모리에 연속하게 저장되어 있기 때문에 O(1)에 인덱스를 가지고 각 원소로 접근할 수 있습니다. 그런데 vector는 배열과 달리 크기를 자유자재로 늘이거나 줄일 수 있다는 장점이 있습니다.
아주 까마득한 후에 그래프의 인접 리스트라는 것을 저장할 때에는 vector를 쓰는게 많이 편해서 vector가 필요하게 되지만 그 전까지는 사실 굳이 배열 대신 vector를 써야하는 상황이 딱히 없습니다. 그래서 당장은 몰라도 크게 상관 없지만 다른 사람이 vector로 짠 코드를 본다고 하면 아무래도 vector를 아는게 좋을 것 같아서 딱 그 정도만 설명을 드리겠습니다.
일단 사용법은 상단의 레퍼런스 사이트에 들어가면 다 익힐 수 있고 앞으로도 가능하면 설명글 보다는 직접 레퍼런스 사이트를 확인하면서 메소드들을 정확하게 익히는게 낫긴 하지만, 익숙하지 않으면 솔직히 좀 힘드니까 그냥 직접 vector를 사용한 예시 코드를 보여드리겠습니다.
직접 타이핑을 해서 확인해도 되고 github 링크에 들어가서 붙여넣기 해도 됩니다. 전반적으로 한 번 보시고, 특히 insert와 erase가 메소드로 이미 구현이 되어 있는 것을 알 수 있습니다. 인자로 v.begin() + x와 같이 주는걸 볼 수 있는데 STL의 iterator 개념을 모르면 조금 낯설 수 있을 것 같습니다. 하지만 설명은 안하고 넘어가겠습니다. iterator의 정체가 궁금하다면 따로 공부를 하시는걸 추천드립니다.
insert, erase는 배열에서 우리가 구현한 것과 비슷하게 시간복잡도가 O(N)입니다. push_back, pop_back은 제일 끝에 원소를 추가하거나 빼는 것이니 O(1)입니다.
생각해보면 당연한 것이지만 이 사실을 깜빡해서 잘못된 시간복잡도로 문제를 접근하는 경우를 막기 위해서 메소드의 시간복잡도를 잘 생각해야 합니다.
또 vector에서 =를 사용하면 deep copy가 발생합니다. 16번째 줄에서 v4는 {1, 2, 4}가 되었고 이후 v4를 바꿔도 v3에는 영향을 주지 않습니다.

vector에 있는 모든 원소를 순회하려고 할 때, 아마 이전에 본 적이 없으실 range-based for loop를 이용할 수 있습니다. 04, 05번째 줄 처럼 int e : v1 이라고 하면 e에 v1의 원소들이 하나씩 들어가는 for문이 됩니다.
지금은 값을 바꾸지 않고 그냥 출력만 해서 별 상관이 없지만, 만약 int e : v1이라고 하면 복사된 값이 e에 들어가고 int& e : v1이라고 하면 원본이 e에 들어갑니다. 그렇기 때문에 int e : v1라고 쓴 for문 내에서 e를 바꿔도 v1에는 영향이 가지 않지만, int& e : v1이라고 쓴 for문 내에서는 e를 바꾸면 원본인 v1에서 실제 해당 원소의 값이 바뀌게 됩니다.
이 기능은 vector 뿐만 아니라 나중에 배울 list, map, set 등에서도 모두 사용할 수 있기 때문에 기억해두시면 좋은데 다만 이 기능은 C++11부터 추가된 기능입니다. 만약 코딩테스트가 C++11을 지원하지 않는다고 하면 사용할 수 없습니다.
2020년 2월 기준으로 제가 아는 범위 안에서는 유일하게 삼성전자 SW 역량테스트만 C++11을 지원해주지 않지만 시간이 지나면 삼성전자 SW 역량테스트에서도 C++11을 지원해주지 않을까 싶습니다.
range-based for loop가 그다지 익숙하지 않다면 아주 무난하게 for문으로 인덱스를 하나씩 다 돌아도 상관없습니다. 2번과 3번이 전부 그렇게 처리하는 코드인데 사실 3번처럼 쓰면 아주 잘못될 수 있습니다.
기본적으로 vector의 size 메소드는 시스템에 따라 unsigned int 혹은 unsigned long long을 반환합니다. 그렇기 때문에 32비트 컴퓨터 기준 3번같이 쓰면 v1이 빈 vector일 때 v1.size() - 1이 unsigned int 0에서 int 1을 빼는 식이 되고, unsigned int와 int를 연산하면 unsigned int로 자동 형변환이 발생하기 때문에 (unsigned int)0 - (int)1은 -1이 아니라 4294967295이 되어버립니다. 4294967295이라는 이상한 값은 unsigned int overflow로 인해 생기게 된 값입니다.
그래서 아무것도 출력을 하지 않고 종료되는 것이 아닌, v1[0], v1[1], v1[2], ... 이렇게 i가 계속 커지다가 어느 순간 런타임에러가 발생하게 될 것입니다.
정리하자면 vector에 있는 모든 원소를 순회하고 싶으면 range-based for loop를 사용해도 되고 그냥 인덱스를 하나씩 다 돌아도 상관없는데, size 메소드의 반환값이 unsigned이기 때문에 3번처럼 구현하면 큰일난다는 것입니다.

vector도 무난하게 됐고 이제는 배열이 쓰이는 문제 몇 개를 다뤄보겠습니다. 일단 배열은 데이터를 자주 바꾸지 않고 그냥 쌓아두고 싶을 때 활용할 수 있습니다. 그리고 사실 거의 대부분의 문제에서 일단 입력값을 저장해놓고 시작하는 일이 많기 때문에 입력을 담아두기 위해 배열을 사용하곤 합니다.
그래서 단지 데이터를 쌓아두는 용도 말고 인덱스에 해당하는 원소를 빠르게 접근하는 목적으로 배열을 사용하면 효율적인 문제를 소개하겠습니다.
첫 번째 문제는 BOJ 10808번: 알파벳 개수 문제입니다. BOJ에 들어가서 문제를 확인하고 또 구현을 끝낸 후에 돌아오도록 합시다.

(정답 코드) 문제를 보면 주어진 단어에서 각 알파벳이 몇 번 나왔는지를 출력하면 되고, 아마 지금의 코드와 같은 아주 자명한 풀이법이 떠오를 것입니다.
코드를 같이 살펴보면 일단 문자열을 입력 받고, 'a'부터 'z'까지 각각에 대해 문자열에 해당 글자가 몇 번씩 등장하는지를 확인합니다. 크게 어려울 것 없는 무난한 문제였습니다.
그런데 지금 이 코드는 문자열 s를 26번 반복해서 확인하게 된다는 것을 알겠나요? 'a', 'b', ··· ,'z'. 각각에 대해 s 전체를 다 살펴보기 때문입니다. 그런데 잘 생각해보면 굳이 같은 문자열을 26번 볼 필요가 없고 한 번만 보면 될거란걸 알 수 있습니다. 방식을 먼저 설명드리겠습니다.

일단 각 알파벳의 등장횟수를 담을 그릇을 다 만들어둡니다.





이후에 주어진 문자열을 한 글자씩 보면서 그릇에 알파벳을 담습니다. 맨 처음의 글자가 a이니까 a를 나타내는 그릇에 1을 추가해주고 그 다음 글자는 b이니까 b를 나타내는 그릇에 1을 추가해주고, 이렇게 모든 글자를 순회하면 문자열을 한 번만 훑어도 될 것입니다.

이걸 코드로 구현하려고 한다면 각 문자의 등장 횟수를 저장하는 freq 배열을 하나 만들어서 처리할 수 있습니다. 'a', 'b', ···, 'z'는 아스키코드 상에서 97번부터 122번까지로 인접하게 붙어있으니 'a'를 0으로, 'b'를 1으로, ···, 'z'를 25로 만들 때 'a'를 빼주면 됩니다. 코드를 한 번 확인해보세요.
일단 freq 배열의 초기값은 0이어야 할텐데 전역에 선언하면 알아서 0으로 채워지니 따로 초기화를 하지 않았습니다. freq가 지역 변수였다면 int freq[26]; 이라고만 할 경우 0이 아닌 다른 쓰레기 값이 채워지기 때문에 int freq[26] = {} 혹은 fill(freq, freq+26, 0); 과 같은 조치가 필요했을 것입니다.
아무튼 s를 입력받은 후 freq[c-'a']++;을 통해 마치 이전 슬라이드에서 본 것 처럼 그릇에 1을 더해줍니다. c-'a'를 해줌으로서 c가 'a'였다면 0, 'b'였다면 1, ···, 'z'였다면 25가 됩니다. 이 부분이 조금 낯설다 싶으시면 아스키코드를 한 번 찾아보세요.

두 번째로 다룰 문제는 0x01강에서 시간복잡도 얘기를 하면서 다룬 문제입니다. 당시에는 이 문제를 이중 for문으로 해결하는 O(N2) 알고리즘을 제시했고 O(N) 알고리즘도 존재한다는 얘기를 살짝 하고 넘어갔는데, 이전 문제와 비슷한 느낌을 잘 이용하면 이 문제의 O(N) 풀이를 떠올릴 수 있습니다.
쉽진 않겠지만 스스로 알아차린다면 굉장히 기쁠테니 지금 종이를 꺼내들고 한 10분 정도만 고민하는 시간을 가지겠습니다. 멈춰두고 충분하게 고민을 한 후에 넘어가도록 합시다.
어째 좀 느낌을 잡으셨나요? 풀어내셨다면 정말 기쁠텐데 많이 어려웠다면 한 번 배워가봅시다.

문제를 O(N)에 해결하기 위해서는 관점을 아주 살짝 바꿀 필요가 있습니다. 이전에는 모든 쌍을 살펴보면서 합이 100이 되는 쌍의 존재 여부를 확인했지만 이번에는 수를 차례로 하나씩 읽으면서 이전에 등장한 수 중에서 지금 보고 있는 수와 더해 100이 되는 수가 있는지를 알고 싶습니다.

예를 들어 현재 53을 보고 있으면, 이전에 등장한 {1, 23} 중에서 53과 더해 100이 되는 수가 있는지를 알고 싶은 것입니다. 이 말을 다르게 표현하면 53과 더해 100이 되는 수는 47이니 이전에 47이 등장했는지를 확인하면 되는 것입니다.
이전에 등장한 모든 수들을 살펴보는 과정을 1, 23, 53, 77, 60 각각에 대해 다 하면 합이 100이 되는 쌍의 존재 여부를 알 수 있습니다.
그러면 예를 들어 현재 보는 수가 60이면 60과 더해서 100이 되는 수는 40이니 {1, 23, 53, 77}에서 40이 있는지를 확인해야 하는데, 이 과정에서 1, 23, 53, 77 각각을 하나하나 다 40과 비교해 같은지 확인한다고 치면 O(N)이 필요합니다. 그리고 이 과정을 N번에 걸쳐 진행하니 시간복잡도는 그대로 O(N2)입니다.

여기서 핵심 포인트는 나와 합해서 100이 되는 수의 존재 여부를 O(N)이 아닌 O(1)에 알아차리는 것이고, 이걸 배열을 이용해서 해결할 수 있습니다. 그 방법은 바로 각 수의 등장 여부를 체크하는 배열을 만드는 것입니다.
원래는 인덱스가 0부터 100까지 있어야하니 101칸의 배열이어야 하지만 공간의 한계로 일부 인덱스만 표시했습니다. 이 배열에서 해당 인덱스의 수가 이전에 등장한 적이 없으면 값이 0, 등장한 적이 있으면 값이 1입니다.


이제 첫 번째 원소인 1부터 시작해보겠습니다. 일단 1과 더해서 100이 되는 수, 즉 99가 이전에 등장했는지를 확인해보면 99번 인덱스의 값은 0이니 99는 이전에 등장한 적이 없습니다. 그리고 다음 수로 넘어갈건데, 그 전에 1이 등장했다는 것을 배열에 나타내줘야 하니 1번 인덱스의 값을 0에서 1로 변경합니다.


그 다음으로는 23입니다. 일단 77이 이전에 등장했는지를 확인해보면 77번 인덱스의 값은 0이니 77은 이전에 등장한 적이 없습니다. 이후 23번 인덱스의 값을 0에서 1로 변경합니다.


그 다음으로는 53입니다. 일단 47이 이전에 등장했는지를 확인하면 47번 인덱스의 값은 0이니 47은 이전에 등장한 적이 없습니다. 이후 53번 인덱스의 값을 0에서 1로 변경합니다.

그 다음으로는 77입니다. 일단 23이 이전에 등장했는지를 확인하면 23번 인덱스의 값은 1이니 23은 이전에 등장한 적이 있습니다. 23이 이전에 나온 적이 있으니 저희는 합이 100이 되는 쌍을 찾아냈습니다. 함수에서는 바로 1을 반환하면 됩니다. 이와 같은 방법으로 문제를 O(N)에 해결할 수 있게 됩니다.

코드는 저희가 다룬 내용을 그대로 차분하게 옮기기만 하면 됩니다. 참고로 if(1){}은 1이 참으로 해석되어 중괄호 안의 내용이 실행되고 if(0){}은 0이 거짓으로 해석되어 중괄호 안의 내용이 실행되지 않기 때문에 04번째 줄을 그냥 if(occur[100-arr[i]])로 써도 동일하게 동작합니다.
혼동을 줄까봐 == 1을 붙이긴 했지만 저는 if(occur[100-arr[i]])와 같이 쓰는 것을 선호하기 때문에 앞으로 코드에서 저런 비슷한게 나와도 당황하지 말아주세요.
N개의 원소를 도는 동안 합이 100인 쌍을 찾지 못했으면 0을 반환하면 되고, 이 코드는 나와 합이 100이 되는 원소를 매 순간마다 O(1)에 찾고 이 행위를 N번 반복하기 때문에 총 시간복잡도는 O(N)이 됩니다.

배열 강의는 여기까지입니다. 다른 내용은 크게 어렵지 않은데 연습문제로 다룬 내용은 아마 낯설 수도 있을 것 같습니다.
어쨌든 고생하셨고 그룹 내의 문제집에 올려둔 문제들을 풀어보도록 합시다. 그럼 다음 시간에 만나요!
'강좌 > 실전 알고리즘' 카테고리의 다른 글
| [실전 알고리즘] 0x06강 - 큐 (14) | 2020.03.11 |
|---|---|
| [실전 알고리즘] 0x05강 - 스택 (47) | 2020.03.08 |
| [실전 알고리즘] 0x04강 - 연결 리스트 (100) | 2020.03.01 |
| [실전 알고리즘] 0x02강 - 기초 코드 작성 요령 II (53) | 2020.02.16 |
| [실전 알고리즘] 0x01강 - 기초 코드 작성 요령 I (80) | 2020.02.12 |
| [실전 알고리즘] 0x00강 - 오리엔테이션 (56) | 2020.02.10 |